
Assessment Arena
Autonomous Grading Infrastructure
AI-Native Evaluation at Scale
Assessment Arena is an AI-native evaluation infrastructure designed to automate the entire assessment lifecycle: dynamic question generation, multimodal answer evaluation (handwritten, typed, or uploaded PDFs), semantic grading, and human-like annotated feedback—all at production scale.
The Problem: Traditional grading systems are binary—right or wrong. Real education requires nuanced evaluation: understanding partial correctness, recognizing alternative approaches, and providing constructive feedback. Automating this requires both deterministic scoring and generative explanation.
The Solution: A hybrid evaluation engine that separates deterministic scoring (rubric-based, reproducible, auditable) from generative feedback (contextual, supportive, personalized). The system ingests multimodal submissions (PDFs, images, handwriting), extracts text using advanced OCR with spatial awareness, applies semantic scoring logic based on curriculum rubrics, and generates teacher-style annotations overlaid on the original answer document.
Key Innovation - Hybrid Grading: Rubric-driven semantic evaluation that uses curriculum-aligned rubrics to score answers according to predefined criteria. Handwritten submissions are processed with spatial memory, allowing annotations to be placed exactly where the student made a mistake—replicating human grading patterns rather than generating generic feedback.
Production Metrics: Processes 200+ papers per hour, semantic grading with rubric compliance, visual feedback overlays that mimic human annotations, PDF rendering with sub-second latency for cached assessments.
Core Technologies
1def generate_assessment(request: dict, user_progress: dict) -> dict:
2 """
3 Curriculum-aware, blueprint-driven assessment engine.
4 Routes models, builds semantic pools, and delegates generation agents.
5 """
6
7 subject = request.get("subject")
8 standard = request.get("standard")
9 test_type = request["test_type"]
10 exam = (request.get("exam_type") or "").upper()
11
12 model = route_model(standard, subject, exam, task="assessment")
13
14 if test_type == "full_test":
15 structure = get_exam_structure(exam) # competitive blueprint engine
16 prompts = orchestrate_full_exam(structure, standard, user_progress)
17
18 elif test_type == "subject_mcq_test":
19 blueprint = get_subject_blueprint() # cognitive mark distribution
20 prompts = generate_structured_test(subject, blueprint, user_progress)
21
22 else: # topic_mastery_quiz
23 prompts = generate_topic_test(
24 topic=request.get("topic_name"),
25 size=request.get("num_questions", 10),
26 progress=user_progress
27 )
28
29 return {
30 "model": model,
31 "mode": "hybrid_agentic",
32 "count": len(prompts),
33 "prompts": prompts
34 }Evaluation Philosophy
The foundation of Assessment Arena is a hybrid evaluation philosophy that balances determinism with generative reasoning. Pure rule-based systems fail in subjective and descriptive answers. The system therefore isolates structured scoring from generative feedback to ensure correctness, reproducibility, and explainability.
Deterministic Core (Rubric + Rule Engine)
The deterministic core is responsible for marks allocation and evaluation consistency. For MCQs, exact match logic applies. For descriptive answers, concept coverage and keyword-weight mapping influence marks.
1# Example of deterministic rubric mapping logic
2def map_rubric_to_marks(rubric, student_response):
3 score = 0
4 for criterion in rubric:
5 if criterion in student_response:
6 score += rubric[criterion]
7 return scoreGenerative Layer (LLM Feedback & Suggestions)
The generative layer does not assign marks directly. Instead, it generates qualitative feedback, improvement suggestions, and contextual explanations. After deterministic scoring is completed, structured evaluation signals are passed into a constrained LLM prompt that produces teacher-style annotations.
Test Generation Architecture
The Test Generation Architecture is responsible for transforming a high-level user intent into a fully structured, evaluation-ready assessment. It is not a simple prompt-to-LLM pipeline. Instead, it is a layered system that enforces structural constraints, difficulty balance, output validation, and cost-aware model orchestration. The architecture isolates test configuration from generation logic, ensuring extensibility across new test types without rewriting the evaluation core.
1class TestGenerationEngine:
2 """
3 Layered architecture that transforms user intent
4 into a fully structured, evaluation-ready assessment.
5 """
6
7 def generate(self, intent: dict, user_context: dict) -> dict:
8 # Resolve configuration (isolated from generation logic)
9 config = resolve_test_configuration(intent)
10
11 # Build structured assessment plan (blueprint + difficulty mix)
12 plan = build_generation_plan(
13 config=config,
14 progress=user_context
15 )
16
17 # cost-aware model routing per section
18 routed_sections = route_models_by_cost(plan)
19
20 # Delegated generation (agentic execution layer)
21 raw_output = execute_generation_agents(routed_sections)
22
23 # Structural + quality validation
24 validated_output = validate_and_balance(
25 raw_output,
26 constraints=config.constraints
27 )
28
29 return assemble_evaluation_ready_test(
30 validated_output,
31 metadata=config.metadata
32 )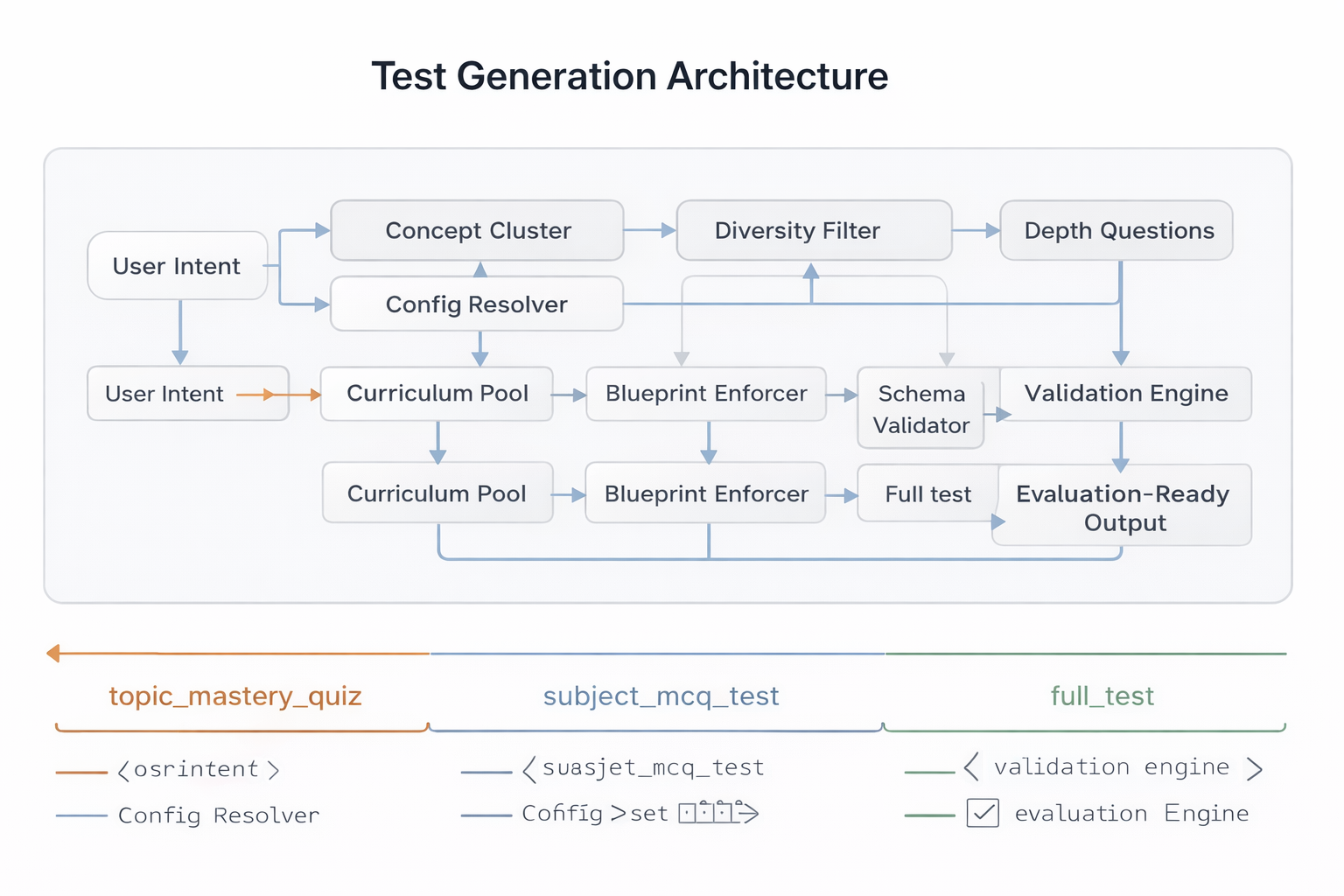
Test Type Abstraction
Test Type Abstraction acts as a configuration layer over the generation engine. Instead of hardcoding logic per test mode, each test type defines constraints such as question format, scoring rules, number of items, and evaluation strategy.
Structured Question Generation
Structured Question Generation ensures that all LLM outputs conform to strict production-ready schemas. Every generation request is schema-bound, validated, retried if malformed, and rejected if structural compliance fails.
Validation Pipeline: The Validation Pipeline performs multi-layer checks including duplication detection, answer-key presence, structural compliance, and semantic sanity checks. This layer ensures production reliability before the test is finalized.
Model Routing Layer
The Model Routing Layer dynamically selects the most appropriate model based on task complexity, modality requirements, and cost constraints. Instead of using a single model for all tasks, routing logic optimizes both performance and expense. Long-form descriptive generation or full_test mode triggers higher-capability models. This layer considers token usage, expected output length, and historical latency metrics before model invocation.
Multimodal Evaluation Engine
The Multimodal Evaluation Engine is the core intelligence layer of Assessment Arena. It enables evaluation beyond structured text inputs by supporting handwritten answers, scanned PDFs, and image-based submissions. The system converts unstructured visual data into structured semantic representations, applies deterministic and semantic scoring logic, and finally generates contextual, teacher-like annotations.
OCR & Layout Parsing
This layer transforms raw visual submissions into structured textual representations suitable for evaluation. The system does not rely on naive text extraction; it reconstructs logical answer structure using spatial and layout cues. Image Preprocessing: Image preprocessing enhances OCR reliability. Submitted images are normalized through contrast enhancement, noise reduction, binarization, and skew correction. For PDFs, each page is rasterized before processing. OCR output includes token-level spatial metadata, which is essential for later annotation placement. Instead of flattening text into a single string, the engine retains positional mapping. The Structured Reconstruction enables segmentation by question number and answer region, allowing independent scoring per question.
Semantic Scoring Engine
The Semantic Scoring Engine evaluates structured answers using both deterministic and embedding-based reasoning. It supports both objective and descriptive question types. Answer-Key Matching: For objective questions, deterministic comparison is applied. The extracted answer is matched against the stored answer key. Exact matches receive full credit, while mismatches receive zero unless partial scoring rules apply.
For descriptive responses, semantic similarity is computed using embeddings or contextual evaluation prompts. The engine evaluates coverage of required concepts rather than exact phrasing.
Annotation System
The Annotation System transforms structured evaluation output into teacher-style feedback placed directly on the answer document. It maps semantic insights to spatial coordinates and overlays contextual comments on the original PDF and uses rubric deviation signals and semantic mismatch thresholds to detect mistakes before generating feedback.
Inline feedback is positioned near relevant answer regions using bounding box coordinates.This mirrors human grading patterns.
Suggestions are constrained to remain aligned with deterministic scoring results.
Marksheet & PDF Rendering System
This layer is responsible for aggregating marks, synthesizing qualitative feedback, spatially mapping annotations, and generating a production-ready annotated PDF. It acts as the bridge between backend evaluation logic and the end-user deliverable.
1def draw_feedback_layer(base_image, visual_data):
2 draw = ImageDraw.Draw(base_image)
3
4 for item in visual_data:
5 # Get coordinates where the student wrote the answer
6 x, y = item['coordinates']
7
8 if item['correctness'] == 1:
9 # Draw a green tick with randomized curve
10 draw_tick(draw, x, y, color=(0, 200, 0))
11 else:
12 # Draw a red cross
13 draw_cross(draw, x, y, color=(200, 0, 0))
14
15 return base_imageRubric-Based Score Aggregation
Rubric-Based Score Aggregation collects question-level scores produced by the Semantic Scoring Engine and merges them according to predefined rubric definitions. Each question has structured metadata including maximum marks, section category, and scoring components.
The aggregation process also preserves traceability by storing intermediate scoring signals such as concept-level contributions. This enables explainability in cases where students or institutions require justification for awarded marks.
Weighted Marks Computation
Weighted Marks Computation applies section-level weight adjustments after raw marks are aggregated. This is critical for full_test mode where descriptive and objective sections may carry different relative importance. Instead of treating all questions uniformly, the system applies predefined weights and recalculates normalized totals.
The weighting logic ensures fairness and curriculum alignment. For example, conceptual reasoning sections may have higher multipliers compared to MCQs.
Annotated PDF Generation
Annotated PDF Generation composes the final graded artifact by layering multiple visual components over the original submission. The base layer contains the student's uploaded document. Above this, annotation layers add highlights, comment callouts, score stamps, and summary sections.
The rendering engine ensures layout integrity by preserving original document proportions while inserting annotations without overlapping critical content. Each annotation is rendered using coordinate mapping derived from OCR processing.
Production Infrastructure
The Production Infrastructure transforms Assessment Arena from a prototype AI system into a reliable, scalable evaluation platform suitable for institutional deployment. The infrastructure is service-oriented, asynchronous where necessary, horizontally scalable, and instrumented for observability and security.
1def get_job_status(job_id):
2 # Atomic read from the job store
3 with DB_LOCK:
4 job = load_jobs().get(job_id)
5
6 if not job:
7 return None
8
9 # Only return the heavy payload when status is 'completed'
10 if job["status"] == "completed":
11 return {"status": "completed", "result": job["data"]}
12
13 return {"status": job["status"]} # Keep payload light while processingAPI & Service Layer
The API & Service Layer acts as the boundary between client applications and internal processing logic. Routes are separated by domain responsibility, each route delegates execution to dedicated service modules, preventing business logic from residing inside controllers.
Async Orchestration
Evaluation and PDF rendering are computationally intensive operations, particularly for multimodal inputs and large tests. Async orchestration ensures that long-running tasks do not block request handling threads. Async orchestration improves throughput and reduces response latency under load. It also prepares the system for queue-based background processing if scaled further.
The Retry & Degradation Strategy ensures that failures in generation, OCR, or scoring do not crash the system.If model output fails schema validation, automatic retries are triggered with corrective prompts. This layered reliability approach prevents catastrophic failure and maintains service availability even under partial degradation.
Observability ensures that the system remains measurable and auditable in production.Security controls protect uploaded student data and prevent prompt injection attacks. Together, observability and security controls ensure that Assessment Arena operates safely, transparently, and at scale.
This Production Infrastructure layer demonstrates that Assessment Arena is architected not just as an intelligent grading engine, but as a scalable, fault-tolerant, production-grade AI evaluation system capable of supporting institutional workloads.