
Text-to-Animation (TTA)
Designing a Reliable Multi-Agent System for Automated Educational Video Generation
AI-Powered Educational Video Generation at Scale
The Text-to-Animation (TTA) Engine transforms raw academic topics into fully rendered, narrated educational videos using deterministic multi-agent orchestration combined with domain-constrained generation. This system solves a critical problem in EdTech: creating high-quality animated explanations at scale without human involvement.
The Core Challenge: Machine learning models generate unreliable code. When asked to write Manim (Python animation library) scripts, LLMs frequently produce invalid outputs—calling non-existent functions, creating structural errors, or generating syntax that fails at runtime. Pure generative approaches fail ~60% of the time in production.
The Engineering Solution: A hybrid neuro-symbolic architecture that uses AI for reasoning while constraining it within deterministic, template-driven structures. Instead of asking the model to invent both logic and structure, we provide strict scaffolds that maximize success rates. This converts an unreliable generative system into a robust production pipeline achieving 99.4% success rate.
Key Innovation - Confidence-Gated Routing: The system analyzes input topics and routes them to domain-specific templates (Physics, Mathematics, Chemistry) only when confidence exceeds 85%. For lower-confidence topics, it triggers a fallback Wikipedia-grounded pipeline. This prevents template mismatches and guarantees usable output for every topic.
Production Results: 99.4% success rate, <100ms audio synchronization, deployment across Physics, Chemistry, Mathematics (PCM) subjects with P95 latency of 85 seconds for video generation.
Core Technologies
The Engineering Gap
The Problem: LLMs lack "Spatial Awareness."
When we began, we simply asked AI models to "write code for a physics simulation." The results were chaotic. The AI would call functions that didn't exist in the library, place text labels on top of diagrams, or write code that simply failed to compile.
We realized that pure generation is unreliable. To fix this, we moved to a Neuro-Symbolic approach: using the AI for high-level reasoning, but confining it within strict, pre-written code structures that guarantee execution safety.
1async def generate_animation(request_data: AnimationRequest, background_tasks: BackgroundTasks, request: Request):
2 # Generates an animation asynchronously by offloading the heavy work to a worker thread.
3 try:
4 # Generate a unique Job ID
5 job_id = str(uuid.uuid4())
6
7 orchestrator: AgentOrchestrator = request.app.state.orchestrator
8
9 concept = {
10 'title': topic,
11 'subject': subject,
12 'description': prompt,
13 'class_level': request_data.class_level,
14 'board': request_data.board,
15 'duration_estimate': 50 #(temporary change)
16 }
17
18 # FUNCTION TO A SEPARATE THREAD (Via BackgroundTasks)
19 background_tasks.add_task(
20 process_animation_background,
21 job_id,
22 concept,
23 user_id,
24 orchestrator
25 )
26System Philosophy: Determinism + Generative Intelligence
Early experimentation revealed that directly prompting an LLM to produce Manim scripts resulted in frequent runtime failures. Undefined objects, inconsistent animation ordering, malformed equations, and structural incoherence made pure generative approaches unreliable.
We therefore adopted a hybrid philosophy:
- Use generative models for reasoning and content synthesis.
- Use deterministic templates to enforce execution structure.
- Use routing logic to ensure domain alignment.
- Isolate failure boundaries to prevent cascading errors.
The system was architected as a staged pipeline where each component has a narrowly defined responsibility and a well-controlled interface.
End-to-End Flow
When a user submits a topic such as "Gauss's Law," the system does not immediately generate animation code. Instead, it first passes through an analysis layer that determines whether the topic belongs to a supported subject domain. This subject classification is performed by a dedicated analysis service that returns both a predicted subject and a confidence score.
The confidence score plays a critical role.If it exceeds a defined threshold, the topic is routed into a subject- specific template engine.If it falls below the threshold, the system triggers a fallback agent pipeline that constructs a structured explanation using Wikipedia as a grounding source before generating animation code.
This confidence-gated routing prevents the system from attempting domain-specific templates on ambiguous or unsupported topics, which significantly reduced rendering failures.

Domain-Constrained Template Architecture
The most important architectural decision was to avoid freeform Manim generation. Instead, we built subject-specific template modules for mathematics, physics, chemistry, and organic chemistry.
Each template is not merely a prompt; it is a structured generation framework.It enforces:
- Scene sequencing rules
- Allowed Manim constructs
- Naming conventions
- Object initialization standards
- Stepwise explanation logic
- Explicit animation boundaries
For example, mathematical topics are structured into introduction, definition, derivation, visualization, and summary phases.Each phase corresponds to a predictable animation pattern.Equations are formatted through constrained rules to ensure proper LaTeX rendering.Intermediate transformation steps are explicitly animated rather than implicitly described.
Physics topics follow a different structure, typically beginning with conceptual framing, followed by diagrammatic visualization, equation introduction, and application examples.Organic chemistry requires arrow- pushing mechanisms and reaction intermediate visualization, which demands even stricter ordering constraints to prevent rendering inconsistencies.
These templates dramatically reduced invalid script generation.Instead of asking the model to invent both logic and structure, we constrained it to fill structured slots within a deterministic scaffold. This approach converted an unreliable generative system into a controllable production pipeline.
1def _get_template_for_subject(self, subject: str, concept: Dict) -> str:
2 # Get appropriate template based on subject and concept
3 # Import templates from separate files
4 try:
5 subject = (subject or "").lower().strip()
6 subject = re.sub(r"[s-]+", "_", subject)
7 subject = re.sub(r"_+", "_", subject)
8
9 from templates.maths_template import MATH_TEMPLATE
10 from templates.physics_template import PHYSICS_TEMPLATE
11 from templates.chemistry_template import PHYSICAL_CHEMISTRY_TEMPLATE
12 from templates.organic_chemistry_template import ORGANIC_CHEMISTRY_TEMPLATE
13 from templates.computer_science_template import COMPUTER_SCIENCE_TEMPLATE
14
15 template_map = {
16 "mathematics": MATH_TEMPLATE,
17 "physics": PHYSICS_TEMPLATE,
18 "chemistry": PHYSICAL_CHEMISTRY_TEMPLATE,
19 "physical_chemistry": PHYSICAL_CHEMISTRY_TEMPLATE,
20 "organic_chemistry": ORGANIC_CHEMISTRY_TEMPLATE,
21 "computer_science": COMPUTER_SCIENCE_TEMPLATE,
22 }
23
24 template = template_map.get(subject, MATH_TEMPLATE)
25 logger.info(f" Using template for: {subject}")
26 return templateMulti-Agent Fallback Mechanism
A system designed for real users cannot reject topics outside predefined domains. To achieve complete coverage, we implemented a fallback pipeline that activates when subject confidence is insufficient.
The fallback mechanism retrieves structured summaries from Wikipedia, extracts core sections, and converts them into animation-ready narrative segments. An orchestrator module dynamically selects tools required for retrieval and synthesis. The fallback generator then produces a generalized but structurally valid Manim script.
The purpose of this pipeline is not domain perfection. It is robustness. The system guarantees that every topic produces a usable video output rather than failing due to template mismatch.
By separating domain-constrained generation from general-purpose fallback generation, we preserved both quality and coverage.
1def generate_wikipedia_fallback_animation(self, topic: str, subject: str,prompt: str = None,
2 language: str = "english",
3 cancellation_callback=None) -> Dict: # Add cancellation_callback
4
5 try:
6 # STEP 1: Determine image count based on prompt
7 prompt_text = prompt or f"Explain {topic}"
8 desired_image_count = self._determine_image_count(prompt_text)
9
10 wiki_data = self._fetch_wikipedia_data(topic)
11
12 script_code = self._generate_wikipedia_manim_script(
13 topic=topic,
14 subject=subject,
15 wiki_summary=wiki_data.get('summary', ''),
16 image_paths=image_paths,
17 prompt=prompt_text,
18 language=language
19 )Orchestration Layer
The orchestration layer acts as the central control system. It decides: Which template to invoke Whether fallback retrieval is required When to trigger script validation How to handle regeneration on failure When to initiate rendering and storage Importantly, orchestration is isolated from generation logic. This separation allows new subjects to be added without rewriting routing code. The system behaves more like a modular agent framework than a single linear script. This modularity also simplifies testing. Each component can be validated independently: classification accuracy, template stability, fallback integrity, rendering success rate.
1class AgentOrchestrator:
2 def generate_animation_for_concept(self, concept: Dict, str = "default_user") -> Dict:
3 # Main entry point: Routes to appropriate generation method (Mostly unused now in favor of _blocking_gen)
4 subject = concept.get('subject', 'mathematics').lower()
5 topic = concept.get('title', 'Unnamed')
6
7 # Route based on subject
8 if self.should_use_wikipedia_fallback(subject):
9 logger.info(f"Routing '{topic}' to Wikipedia fallback (subject: {subject})")
10 return self.generate_wikipedia_fallback_animation(
11 topic=topic,
12 subject=subject,
13 prompt=concept.get('description', ''),
14 with_audio=with_audio,
15 user_id=user_id
16 )
17 else:
18 logger.info(f"Using core engine for '{topic}' (subject: {subject})")
19 return self._generate_core_subject_animation(concept, with_audio, user_id)
20
21 def _generate_core_subject_animation(self, concept: Dict, cancellation_callback=None) -> Dict:
22 # Optimized animation generation with Parallelism and Draft Mode
23 try:
24 gen_result = self.code_generator.generate_code(concept, template, cancellation_callback=cancellation_callback)
25 manim_code = gen_result['code']
26 scene_list = gen_result.get('scene_list', [])
27
28 final_code, render_result, script_path = None, None, None
29 actual_duration = target_duration
30
31 current_code = validation['code']
32 if not render_result or not render_result['success']:
33 logger.error("All render attempts failed. Using fallback.")
34 final_code = self.create_fallback_animation(topic)
35 script_path = self.save_script(topic, final_code)
36 render_result = self.render_manager.render_animation(script_path, cancellation_callback=cancellation_callback, quality_override="low")
37 self.stats['fallback_used'] += 1
38
39 video_path = render_result['video_path']
40 actual_duration = render_result.get('duration', target_duration)
41
42 final_video_path = video_path
43 Script Validation and Rendering
Generating code is not equivalent to executing it successfully. Manim rendering is sensitive to syntactic correctness and object lifecycle management. After script generation, the system performs structural sanity checks before invoking the Manim CLI. Rendering exceptions are captured and logged. If failure occurs due to script issues, regeneration can be triggered within controlled retry limits.
Rendering is treated as a separate execution phase rather than an extension of generation. This design prevents long-running animation tasks from blocking API responsiveness and allows scaling rendering workers independently if needed.
Narration and Synchronization
The animation includes synchronized narration. Instead of embedding narration blindly within visual logic, we separate explanation text into structured blocks. These blocks are processed through a text-to-speech engine, generating segmented audio files.
Audio is aligned with scene transitions to prevent drift. By decoupling narration from animation code, we preserve clarity, allow independent iteration on voice models, and avoid tight coupling between visual and auditory layers.
1audio = tts.generate(narration_text)
2merge(video_path, audio)Cloud Storage and Asset Lifecycle
Once rendered, the final video is uploaded to Google Cloud Storage. This decision decouples compute from storage and ensures durability, scalability, and global access performance.
The system returns a public asset URL upon successful upload. Versioning strategies allow re-rendered topics to overwrite or archive previous versions. This architecture supports horizontal API scaling without entangling storage concerns with compute instances.
1blob.upload_from_filename(video_path)
2url = blob.public_urlReliability Engineering
The system anticipates failure modes at every stage:
- Subject misclassification is mitigated via confidence gating.
- Invalid animation constructs are reduced through template enforcement.
- Rendering crashes are captured and logged.
- Wikipedia retrieval failures trigger fallback handling.
- Infinite regeneration loops are prevented through bounded retries.
The philosophy is defensive engineering rather than optimistic generation.
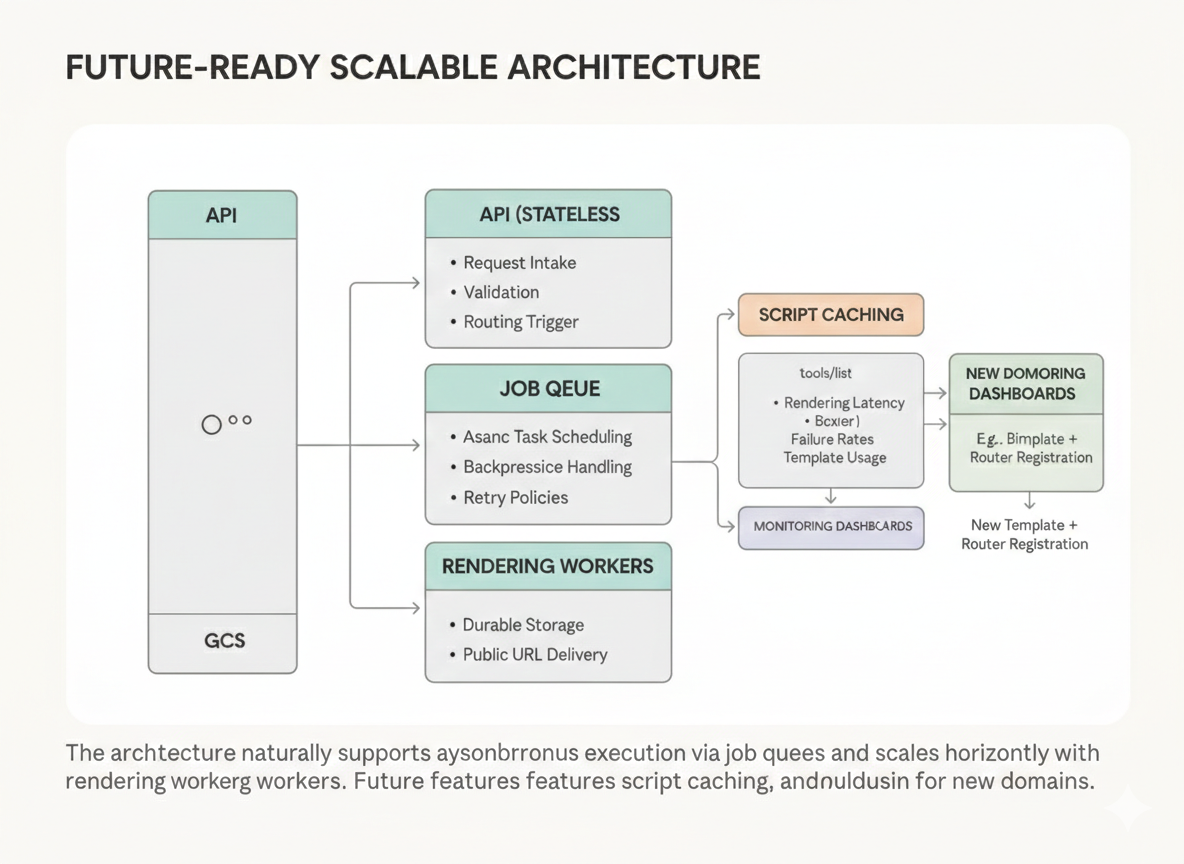
Scalability and Future Evolution
The architecture naturally supports asynchronous execution via job queues. Rendering workers can be scaled horizontally. Script caching could eliminate redundant regeneration for popular topics. Monitoring dashboards could track rendering latency, script failure rates, and template usage distribution.
Because orchestration is modular, adding new domains—such as biology or economics—requires only implementing a new constrained template and registering it with the router.
Technical Depth Demonstrated
This system demonstrates:
- Practical LLM reliability engineering
- Structured code generation strategies
- Multi-agent orchestration design
- Domain-aware routing with confidence gating
- Production-safe fallback architecture
- Cloud-native asset management
- Separation of concerns across pipeline stages
The project moves beyond prompt experimentation into system-level AI engineering. It reflects an understanding that production AI systems must be robust, modular, observable, and defensively designed.